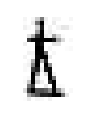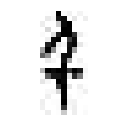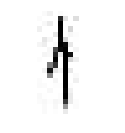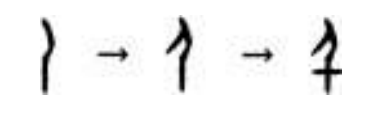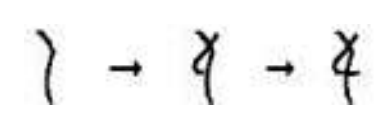马上注册!
您需要 登录 才可以下载或查看,没有账号?注册
×
【一线讲述】 作者:聂菲(南京大学文学院助理研究员) 古文字,主要指中国商代晚期至秦代使用的汉字。二十世纪30年代,殷墟发掘出大量有字甲骨,证实了商王朝的存在,重塑了世界对中国古代文明的评价。近年,抄有《老子》《诗经》等内容的战国竹书呈井喷式涌现。可以说,古文字是解读中华文明基因的关键。 古文字研究与科技发展密不可分。红外采集、高精度扫描等技术手段极大改善了资料条件,索引、搜索引擎、数据库,为古文字研究提供了巨大助力。如今,AI技术蓬勃发展,当通过人工智能拼缀上第一片甲骨时,实现的不仅是技术突破,更是中华文明根脉的赓续与新生。 简单来讲,“破译”古文字可分为两步:一是识形,二是读词。即先认出古文字形体是什么字,再判定其音义,弄明白它在文献中的含义。如,先认出甲骨中“[图1]”是“王”,再读懂刻辞与商王有关。人工智能辅助古文字研究,就是要模仿人类专家的学习过程,进行“记字形”和“读古书”的训练。 图1 目前对计算机而言,“认字形”十分艰难。机器学习面临着诸多挑战,包括图像预处理结果不佳、标注样本稀缺、字形实情极其复杂等。其中,“数据困境”是显性瓶颈,古文字单字量低,有效样本密度低,机器学习样本不足。最近,我所在的课题组参与开发了“古文字线上书写系统”,旨在收集专家书写古文字的动态路径,将古文字字形转换成有顺序、有方向的矢量线段,为训练计算机识读字形提供学习参考。 此前计算机识图多从像素角度入手,受图像质量、样本量、字形复杂性等影响,特征提取困难,识别率低。为了破题,我们课题组转换了思路——并非让模型分析静态字形,而是通过动态路径数据,捕捉专家的书写顺序和对字形结构的理解,帮助模型像人一样“思考”如何书写古文字。我们希望通过提取人类书写古文字的动态特征,将人的经验转换成可训练的数据规则,从而弥补传统方法在异体字处理上的缺陷,解决数据量不足等问题。 目前,我们的研究已进入初步试验阶段,录入了12825条字形书写数据进行前期测验。眼下正在搭建机器学习的模型,相关代码达到万余行,计算机累计运行时间超过400小时,模型迭代3个版本。从生成结果看已初见成效,计算机能成功模仿人类书写的笔势、笔顺和大致轮廓,但在部件书写的准确性、笔画组合和构件位置关系上,仍有很大的进步空间。 图2 图3 例如甲骨文中“千”字有一类形体作“[图2]”形,是在侧视站立人形“[图3]”的基础上,在其腿部加一横笔分化而来,其书写顺序一般是先写出侧视身体躯干和手臂,再写后加的一横笔: 目前训练得到的机器书写路径是: 可以看出,计算机已能再现字形轮廓和笔顺,但对第二笔的起始位置把握欠佳:第二笔不应与第一笔交叉穿出;二、三笔虽顺序相接,但笔迹并不相连,即第二笔的终点并非第三笔的起点。 为修正结果,我们将在现有试验的基础上,对机器学习方法和算法结构进行调试和整改。这项工作可能十分漫长,但也蕴含着无限潜力。 《光明日报》(2025年06月10日 14版)
|  关注公众号
关注公众号 QQ会员群
QQ会员群


 发表于 2025-6-10 09:19:52
发表于 2025-6-10 09:19:52